DBの負荷分散の手法について世の中にある手法についてかなり忘れてしまってきているので、最勉強を兼ねてざっくりと調べてみました。
設計の見直しとチューニング
負荷分散では無いですが、分散設計を考える前に、設計の見直しや、チューニングで救えるケースの方が多いと思うので少しだけ。
設計の見直しやチューニングをしないと、無限にリソースが必用になるので、ここはある程度きちんとやった方が良いと思う。(オンプレでは新規 HWを調達するのは難しいので、通常これをやるしかなくなる)
DBの設計を見直す
正規化(データの冗長製の排除)だけだとデータ結合が必用になる事がありパフォーマンスに問題が出ることがある。非正規化(データを冗長に持つ)事も考える。
「スケールアウト」の所で後述するが、既存の DB でデータのリレーションが薄いものは、別 DBとして分割する事で負荷分散される事もできる。
DBのチューニング
設計は正しくても実際の運用で、どのような SQL が多いのか等を正確に予測する事は難しい。そのため実際の使われ方を反映した調整をする必用がある。
不要な実行コスト (負荷)の高い SQL をアプリ側で投げないようにアプリ側を改修する方法もあるし、アプリ側の負荷が高いのであれば、DB内で処理が完結する「ストアード・プロシジャー」を使うと速くなる可能性もある。
表の再編成
長い間使っているとデータの削除なので、データの断片化が起きる。
物理的に必用なデータが分散してしまう事で、データの捜索に時間がかかるようになる。
データを綺麗に並べ直してあげる(再編成) 事で、データを再び高速で検索してあげる事ができるようになる。
表の再編成については、DB毎に実装が違いお作法が違うが、統計情報を取得し、必用な表を再編成するという概念は同じである。
またこれらの処理は、基本的に負荷が高く、更新をブロックしたり、オンラインでできない場合もあるので、各DBの注意書きをよく読んで実行する。
- DB2 の場合、RUNSTAT で統計情報を取得、REORGCHK で再編成を推奨するテーブルを割り出し、REORG で表に対してコマンドで再編成を行う。オンラインでもできるが、IO負荷が高いのでメンテナンス時間にやった方が良い(参考)。
- Oracle の場合、ANALYZE TABLE でテーブルの統計情報を取得し、ALTER TABLE を使用する(参考)。
- MySQL の場合、OPTIMIZE TABLE コマンドを使う事で可能。MySQL 5.5 より前では、MyISAM(マイアイサム) がデフォルトのストレージ・エンジンで、MySQL 5.5 以上では、InnoDB (イノディービー) がデフォルトのストレージ・エンジンになるが、これによっても動きが違う。InnoDB では、統計情報を取得する ALALYZE TABLE が自動で走る (参考1, 参考2)
アクセスパスを調べる
SQLを実行した時に目的のデータにたどり着くまでどういうアクセス手順を実行するかは、実行計画 (アクセスプラン)や 「アクセスパス」と呼ばれる。
例えば 1000行のテーブルから、特定の一行を見つけるために、テーブルのデータを全部チェックする方法もあるし、インデックスが上手く貼られていてインデックスを使って目的の行だけをピンポイントで探す事ができるのであれば、後者方が圧倒的に速くなる。
どの DBMS も、実行する SQL が内部的にどう実行されているか分析ツールを持っている。
Oracle, MySQL や DB2 等で、 EXPLAIN コマンドと呼ばれている。
- 無駄なテーブルスキャンをしていないか
→ 無駄なテーブルスキャン (全表スキャン) は、表全体を読み込まないといけないので、大量にリソースを使用する。インデックスを上手く貼って解決できる場合がある。 - カーディナリティのチェック
→ 分散度が高い(カーディナリティが高い)カラムに Index を貼る → 絞り込みが早くなる
等などプロの方に相談するといろいろ出てくる。正直、もっと勉強しないわからないのでこの辺りで・・・
参考:
- 津島博士のパフォーマンス講座 第8回 断片化について - Oracle。DBのデータの断片化について
- DB2 SQLアクセス・パスのチューニング- DB2
- パフォーマンス維持のための運用 (REORG と RUNSTATS) 編 - DB2
- データ・アクセス・パスの最適化 - Oracle
- SQL実行計画の疑問解決には「とりあえずEXPLAIN」しよう - MySQL
- 【SRE】成長するサービスとDB負荷との闘い - MySQL の運用記事
- アクセスプラン(実行計画)の読み方入門 35 - DB2 のアクセスプランの見方
- DB論理設計のノウハウ - Qiita
スケールアップ
HWの処理能力を追加する事で DBの性能を上げる。
CPU / Memory / Disk (IOPS) の追加
物理筐体の限界に縛られるが、とりあえずしのげれば良い場合はこちらで良いと思う。
IOPS の追加
CPU とメモリの追加はよく知られていると思うが、ストレージについての議論はあまりみかけないので、IOPSについて追記。
一般的にストレージ屋さんはその処理能力を IOPS と 帯域 (Mbps) でサイジングをする。
アプリケーションの処理能力を拡張する場合は、一般的に IOPS (一秒間に処理できる、ディスクの IO数) の指標を増やす事を考える。
帯域 (Mbps) は、バックアップなど決められた時間に大量のデータをどこかに送信しないといけない時のサイジングに使うもので、帯域を増やしたからと言って IOPS が増えるとは限らない。
帯域がボトルネックになってIOが詰まっている場合も無いとは言わないが、通常、IOPS は帯域がスカスカで頭打ちになっている。
IOPS は、ストレージ・コントローラーのキャッシュメモリを増やしたり、LUNに含まれるディスクの本数を増やす事で増やす事が出来るが、手っ取り早いのは、SSD や Flash 等の Static メモリ系のデバイスを使う事になる。
クラウドサービスでは、プロビジョンド IOPS SSD (io1) ボリューム のように 、100 IOPS ~ 64,000 IOPS の間 (2020年3月現在)で好きな量の IOPS のボリュームをプロビジョニングできる。
スケールアウト (シャーディング)
テーブル分割の視点で語ると、テーブルの水平分割と垂直分割がある。どちらもテーブルを断片(shard) 化するので、「テーブル・シャーディング」と呼ばれる。
DBMS 視点で語ると、DBMS は単一で、テーブル毎に配置するストレージを分割する (テーブルシャーディング)と、DBMS 自体を分割してしまう手もある ( DBMS シャーディング)
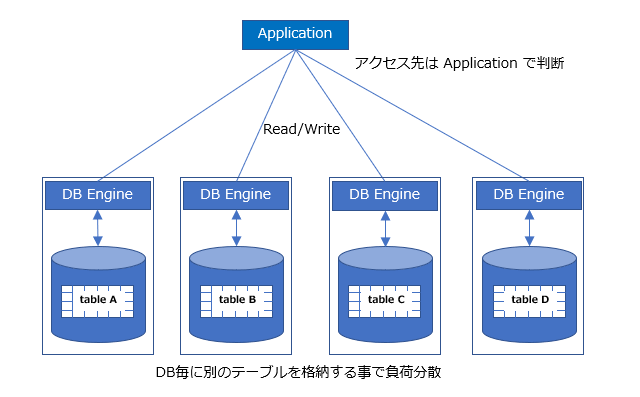
垂直分割
- 例えば、ID がキーだとすると ID と会社名、出身地、住所、生年月日 が一つの表に入って居るとする。
別に一度に引き出す必用がなければ、 table A (ID +会社名) 、table B (ID+出身地)、table C (ID+住所) の 3つの別々のテーブルに分ければ DBを分割できる。 - デメリット:何かあった時にデータの不整合が起きやすい。例)Table A と Table B 上のデータに関連があり、Application が Table A を更新した後ストップした場合。ネットワーク越しで、異なるDBのデータを処理するため通信障害に見舞われやすい。
- テーブル毎にDBを分ける「縦割り」構成
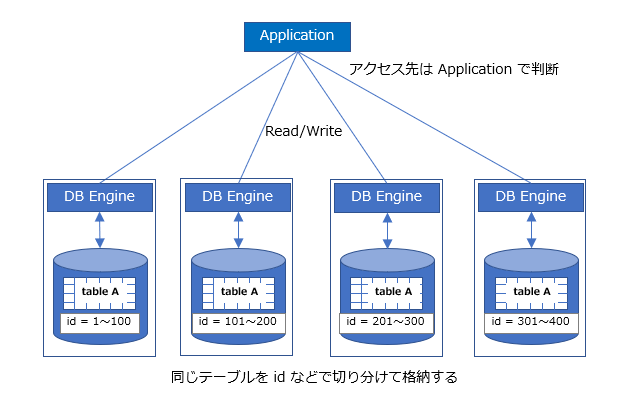
水平分割
- 例えば、ユーザー毎にユニークなID があり、それをキーとすると、ID 1~10,000 10,001 ~ 20,000 のように、IDのレンジでDBを分割していく。
- ソーシャルゲーム界隈では、水平分割が一般的のようだ (参考1, 参考2, 参考3)
- DWH では、月 / 週 / 日ごとのようにテーブルをレンジで分けやすいので良く使われる。
参考:
- 【セミナー】「これで怖くない!? 大規模環境で体験するDB負荷対策~垂直から水平の彼方へ~」垂直分割から水平分割への移行実現とその課題 - FGO の事例。簡単な垂直分割で乗り切ろうとしたが、限界が来て水平分割の一本化に。
- ソーシャルゲーム案件におけるDB分割のPHP実装 - 水平分割と垂直分割についての概要
- シャーディングとは、テーブルシャーディングという可能性【水平分割】 WEB制作・開発実例・コラム
スケールアウト (レプリカ方式)
マスターに加えて、レプリカの DB を用意する方法。MySQL 等で主にサポートされている。
「マスター + レプリカ構成」と呼ばれたり「更新系 + 参照系構成」と呼ばれたりする。
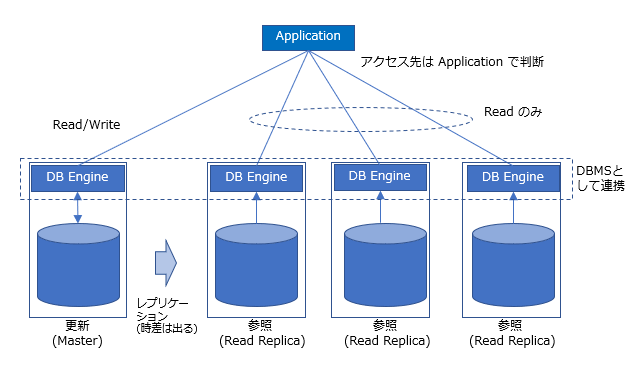
DBMS は単一だが、更新用の DB と、リードオンリー(参照のみ)のレプリカを作ってアクセスを分散させる。但しこの方法は更新系についてはスケールしないので、リードが多いDBであるのかどうか考える。
アプリケーションサーバで、更新系 Query と 参照系 Query を割り振る。
過去の履歴やデータ分析をするためのアクセスは、Write が必用なく Read のみのため、DWH (DataWarehouse) 目的で「参照系DB」を作成するケースがある。
参照系へのレプリケーションに追いつかないときは、データの不整合が出る可能性があるがどうすれば良いか?
→ 根本的な解決は無い。アプリ側で気を付ける(MySQL の準同期機能は、アプリにコミットを返す前にログまではレプリカに書くけどテーブルまでの反映までは保証しない)
レプリカの機能を、短時間でDBのデータを他の場所に移行するための手段として、使用するケースもある。
参考リンク:
- DBサーバーの負荷分散 MySQL での負荷分散
- リードレプリカのスケールアウト(データベースの負荷分散)
スケールアウト (ノード追加で DBMSの処理能力を増加)
Enterprise 系の Database 製品のみで見られる方法で、全てのノードがアプリケーションからのクエリーを処理する事ができ、ノードの追加でスループットがスケールしていく。

この方式はどの DBノードにアクセスしても、DBノード間でアクセス競合を処理してくれるため、アプリケーション側でデータの種類や Read/Write の違いでアクセスノードを変更するロジックを組み込む必用が無い。アプリケーションサーバー、DBMS層、ストレージの間で疎結合な構成を実現できるため、負荷が高い部分だけをスケールさせる事ができる。
ノード間は 高速な Ethernet や、InfiniBand 等の低遅延ネットワークで結合されて、ノード間はお互いに通信をしながら同期して動く。ノード間の通信は一般のユーザーのネットワークと分離されたネットワークを使って行われる。
筐体の限界を超えたスケールアップのような性質もあると言っていいかもしれない。
DBMS の処理はノードの追加でスケールアウトするが、一般的に共有ディスクが用いられる。
もし、ディスク部分の IOPS がボトルネックになっている場合は、ディスク部分のIOPSはストレージ・システム側で独立してスケールアップを考える。
Oracle RAC (Real Application Cluster)
ノード間を最低 1Gbps のインターコネクト回線で接続する。インターコネクトはノード間通信専用線として使用され、「Cache Fusion」と言う方法でノード間でデータブロックを直接やりとりする事で、DBへのアクセス競合を解決。
RAC の前身である OPS では、共有ディスクを介してアクセス競合を制御していた(参考)
IBM DB2 PureScale
Infini Band でのノード間を接続したノードのクラスタを作成する。基本的にノードを追加すると処理能力はリニアに増えていき、ノードの数を2倍にするとスループットも2倍になる(参考1)
各ノードは、ロック情報等を管理するCF (Coupling Facility) にアクセスし同期を取る。CFノードは Primary と Secondary で冗長化される。
InfiniBnad 上で Remote Direct Memory Access(RDMA)を使用して、IPレイヤーの通信を経由ぜずに、CF のメモリを直接更新できる(参考)
分散ストレージの GPFS を使って地理的にノードを分散させる GDPC という構成もある。
参考:
- Oracle Real Application Clusters(Oracle RAC)のキモ ~Cache Fusionに注目する~ - Oracle RAC の Cache Fusion のアーキテクチャー
- 既存の共有ディスク型アーキテクチャの弱点を克復したIBM DB2 pureScale
- 地理的に分散した Db2 pureScale クラスター (GDPC)
スケールアウト(クラウドサービス)
ノード追加をして処理能力を拡張するものだが、ネットワーク的に分散した環境で用いられるため、オンプレで使用されるものよりノード間の通信速度は遅いと思われる。
そのため、ノード間の合意形成の通信時間がより必用で、処理できるトランザクション量は、オンプレ型のシステムよりは物理制限で遅くなると想像される。
ただし AWS の用に Availability Zone をストレージの遅延ができるだけ小さくなるような距離において分散したストレージに同期書き込みが素早くされているなどの工夫が見られるものもある。
またネットワークの分断によるノード分断も起きやすくなる。
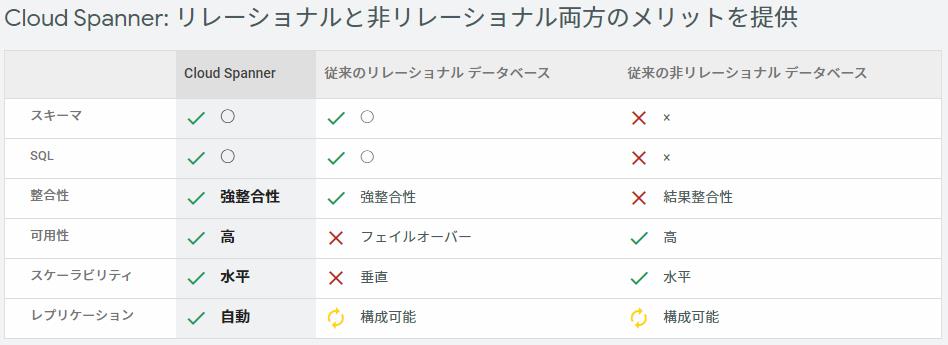
GCP Cloud Spanner
- マルチマスターの MySQL のようなものを目指して開発がはじまったとされている。
- ノードをつなぐネットワークはインターネットでは無く、Google が保持するプライベートネットワークである。
- 分散DB環境で不整合を起こさせない Paxos という合意形成アルゴリズムを使用している。
- 分散環境での合意形成アルゴリズムは、合意形成までネットワーク間で数回のやりとりが発生するため、ある程度の遅延はさけられない。そのため 既存の Oracle RAC / IBM Db2 PureScale のように物理的に高速なバスでノード間が接続されたソリューションの移行ではパフォーマンスのの問題がでる可能性があると思われる。( IP ネットワーク環境では、msec のオーダーの通信で競合しないための合意形成をする必用があるが、Db2 PureScale 等で使われる RDMA では、InfiniBand を使用した nsec のオーダーで競合解決が行われる。Cloud Spanner では1,000倍のオーダーでの遅延が物理的に存在する)
- CLOUD SPANNER ここで比較されている「従来のRDB」はオープンソース系 MySQL などの事で、エンタープライズ系で用いられている Oracle RAC / IBM Db2 PureScale 等は考慮されていない。
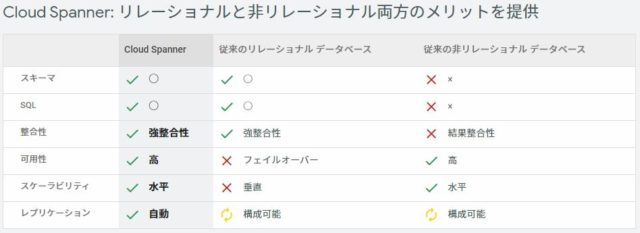
- 可用性 SLA は、99.999% (0.43分/月) が定義されている。
参考:
AWS Aurora
- AWS の RDS (Relational Database Service) をクラスター化したサービス。MySQL 互換と PostrgreSQL 互換の2種類がある。
- 更新系ノード(マスター)と 最大15の 参照系ノード(レプリカ)がある。合計ノードは最大 15。更新系ノードが死んだ場合は、参照系ノードが昇格する。
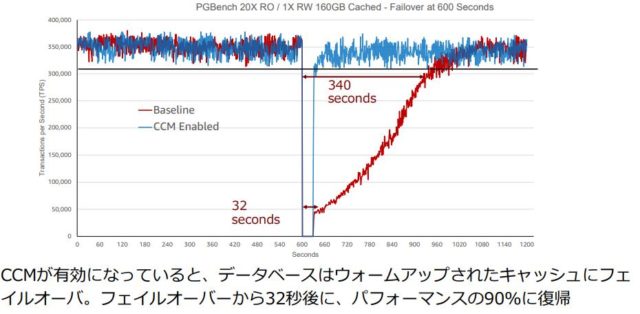
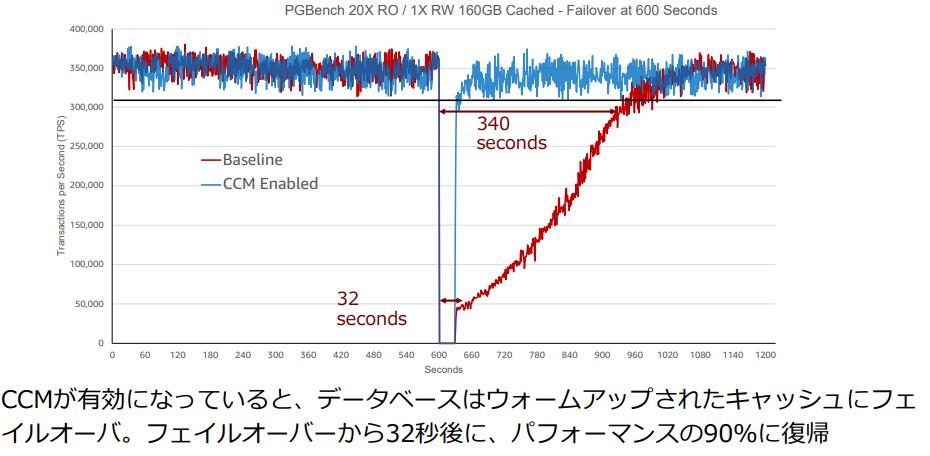
- 「CCM: クラスタキャッシュ管理機能」を使い、更新系ノードのキャッシュを特定のレプリカに同期させておく事ができ、参照系の昇格時にキャッシュを維持し パフォーマンスの劣化に繋がる DiskIOの 増加を最小に抑える事ができる (参考)
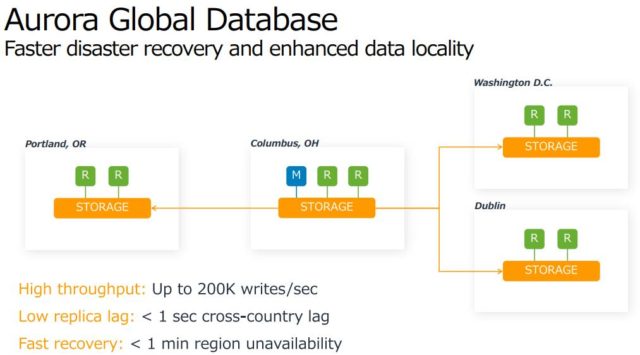
- データは6ノードに非同期・並列で書き込む。データは1つの AZ 内でコピーを持つように作られ、さらにそれが 3つの AZ間でもコピーされる。合計で 6つのコピーを持つ。
- 通用は Master - Replica 間で使用される Storage は分散ストレージでデータは同期されているが、DR (Disaster Recovery) 用に、Master と Replica をリージョンに分散させて、非同期レプリカも構成できる(参考)。
- Amazon の Fullfilment Center は、Oracle から Aurora に乗り換えた。
- 可用性 SLA は、99.99% (4.3分/月) が定義されている (2020/03/22現在。以前は 99.999%だった)

参考:
- AWSのデータセンターの中身を、設計総責任者が話した (1/2)
- AuroraかRDSどちらを選ぶべきか比較する話をDevelopers.IO 2019 in OSAKAでしました #cmdevio Aurora の中身について。Developers.IO
- Deep Dive on Amazon Aurora - AWS エンジニアによる解説資料
NoSQL の分散ストレージ系のDBに移行する
そもそも論ではあるが、RDBである必用がなければ NoSQL 系の分散ストレージを持った DB に移動する。
ノードを追加する事でスケールアウトする事ができる。
NoSQL と言えども、SQLライクだったり、最近ではSQL の構文が使えるものがある。
Azure Cosmos DB
グローバルに分散できる No SQL DB
分散による遅延によるデータの不整合をユーザーがどこまで許容できるかを、確実に一貫性を保証する状態から、「t 秒後以降は k世代以内のデータが読める事を保証 (t と k はユーザー指定)」等、5段階から選択する事ができる(参考)
参考:
- 謎の分散データベース「Azure Cosmos DB」一問一答 Azure の Technology Specialist へのインタビュー記事
- Azure Cosmos DB 公式ホームページ
Web三層の負荷分散
[blogcard url="https://www.engineer-memo.net/20200224-5011"]
[blogcard url="https://www.engineer-memo.net/20200305-5291"]